|
|
|
|
I am an incoming Assistant Professor at the University of Michigan (starting Fall 2027), joining the Robotics Department with an affiliation in Computer Science. I am currently a Senior Research Scientist at NVIDIA. My lab will work on robot learning, dexterous manipulation, robot foundation models, and 3D perception. I am looking for students to join me; see my FAQs for Prospective Students. I completed my Ph.D. in CS at Princeton University, advised by Prof. Jia Deng, and have been fortunate to work with pioneers in AI including Dieter Fox, Vladlen Koltun, Prateek Jain, and Shrikanth Narayanan. I am an RSS Pioneer and a Qualcomm Innovation Fellow. A common thread in my work is finding the simplest possible solution to complex problems. My contributions span robot learning, manipulation, and 3D Vision. My work has been covered by MIT News, Hacker News, The Robot Report, and NVIDIA Blog. My open-source code has cumulatively garnered over 1,500 stars on GitHub (VLA-0, RVT, Non-Deep Networks, and SimpleView) and is used by researchers worldwide. 
|
|

|

|

|

|

|

|

|
| Research Scientist NVIDIA Current |
PhD, CS Princeton University 2018 - 2022 |
Research Intern Intel Winter 2021 |
MS, CSE University of Michigan 2016 - 2018 |
Research Intern MSR Summer 2016 |
Research Intern USC Summer 2015 |
BTech, EE IIT Kanpur 2012 - 2016 |
|
|
Older news
|
|
|
|
We introduce VLA-0, a surprisingly simple approach to building Vision-Language-Action models that achieves state-of-the-art results by representing actions directly as text, without any architectural changes to the base VLM. VLA-0 outperforms all methods trained on the same robotic data on LIBERO benchmark and even surpasses models with large-scale pretraining. |
|
|
Evaluation is a critical bottleneck in building robot foundation models. RoboLab is a high-fidelity simulation environment for testing these models. A truly generalist policy should be able to complete these tasks zero-shot, and this benchmark highlights exactly how far we still have to go. |
|
|
ManiFlow is a visuomotor imitation learning policy for general robot manipulation that generates precise, high-dimensional actions in just 1-2 inference steps using flow matching with consistency training. |
|
|
We introduce HAMSTER, a Hierarchical Vision-Language-Action (VLA) architecture designed for robotic manipulation. This approach effectively combines the advantages of imitation learning models, which require little in-domain robot data, with those of large VLA models that can generalize well. |
|
|
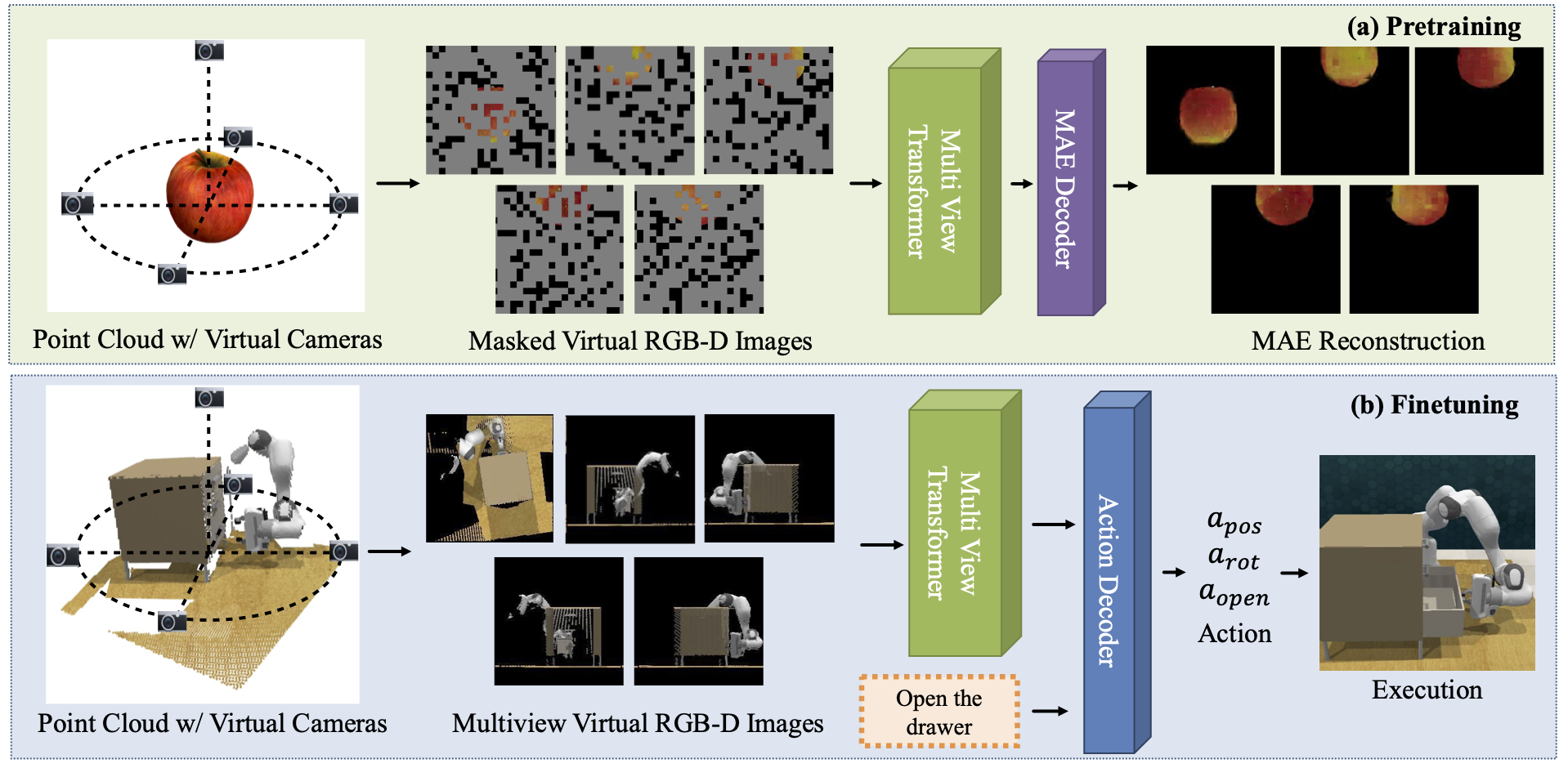
We propose 3D multi-view pretraining using MAEs for robot manipulation. |

|
We study how to build a robotic system that can solve high-precision manipulation tasks from a few demonstrations. Prior works, like PerAct and RVT, have studied few-shot manipulation; however, they often struggle with tasks requiring high precision. We study how to make them more effective, precise, and fast. Using a combination of architectural and system-level improvements, we propose RVT-2, a multitask 3D manipulation model that is 6X faster in training and 2X faster in inference than its predecessor RVT. RVT-2 achieves a new state-of-the-art on RLBench. |

|
RVT is a multi-view transformer for 3D manipulation that is both scalable and accurate. In simulations, a single RVT model works well across 18 RLBench tasks with 249 task variations, achieving 26% higher relative success than existing SOTA (PerAct). It also trains 36X faster than PerAct for achieving the same performance and achieves 2.3X the inference speed of PerAct. Further, RVT can perform a variety of manipulation tasks in the real world with just a few (~10) demonstrations per task. |
|
RPDiff rearranges objects into "multimodal" configurations, such as a book inserted in an open slot of a bookshelf. It generalizes to novel geometries, poses, and layouts, and is trained from demonstrations to operate on point clouds. |
|

|
Infinigen is a generator of unlimited high-quality 3D data. Procedural and open-source. |

|
We use large language models (LLMs) for task planning in robotics. We construct pythonic prompts, which specify the task, robot capabilities and the environment to seed LLMs. |

|
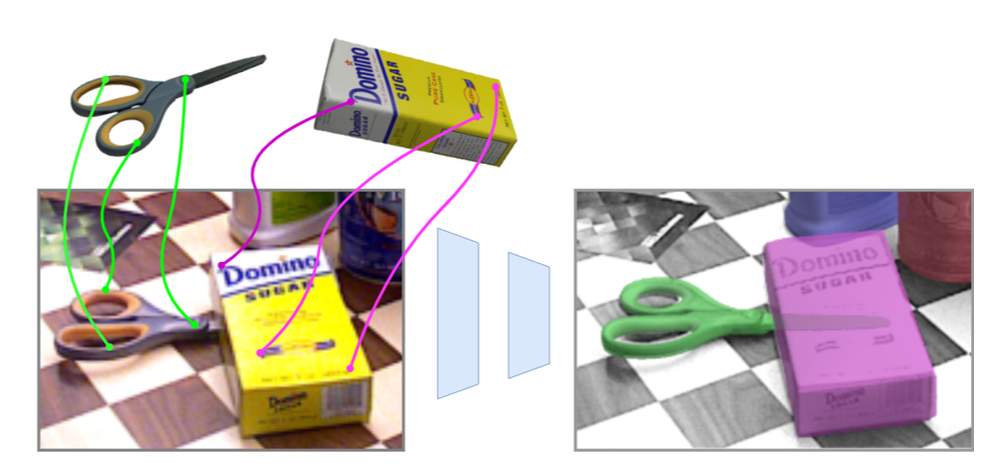
IFOR is an end-to-end method for the challenging problem of object rearrangement for unknown objects given an RGBD image of the original and final scenes. It works on cluttered scenes in the real world, while training only on synthetic data. |
|
We propose state-of-the-art 6DOF multi-object pose estimation system. Our system iteratively refines object pose and correspondece. |
|
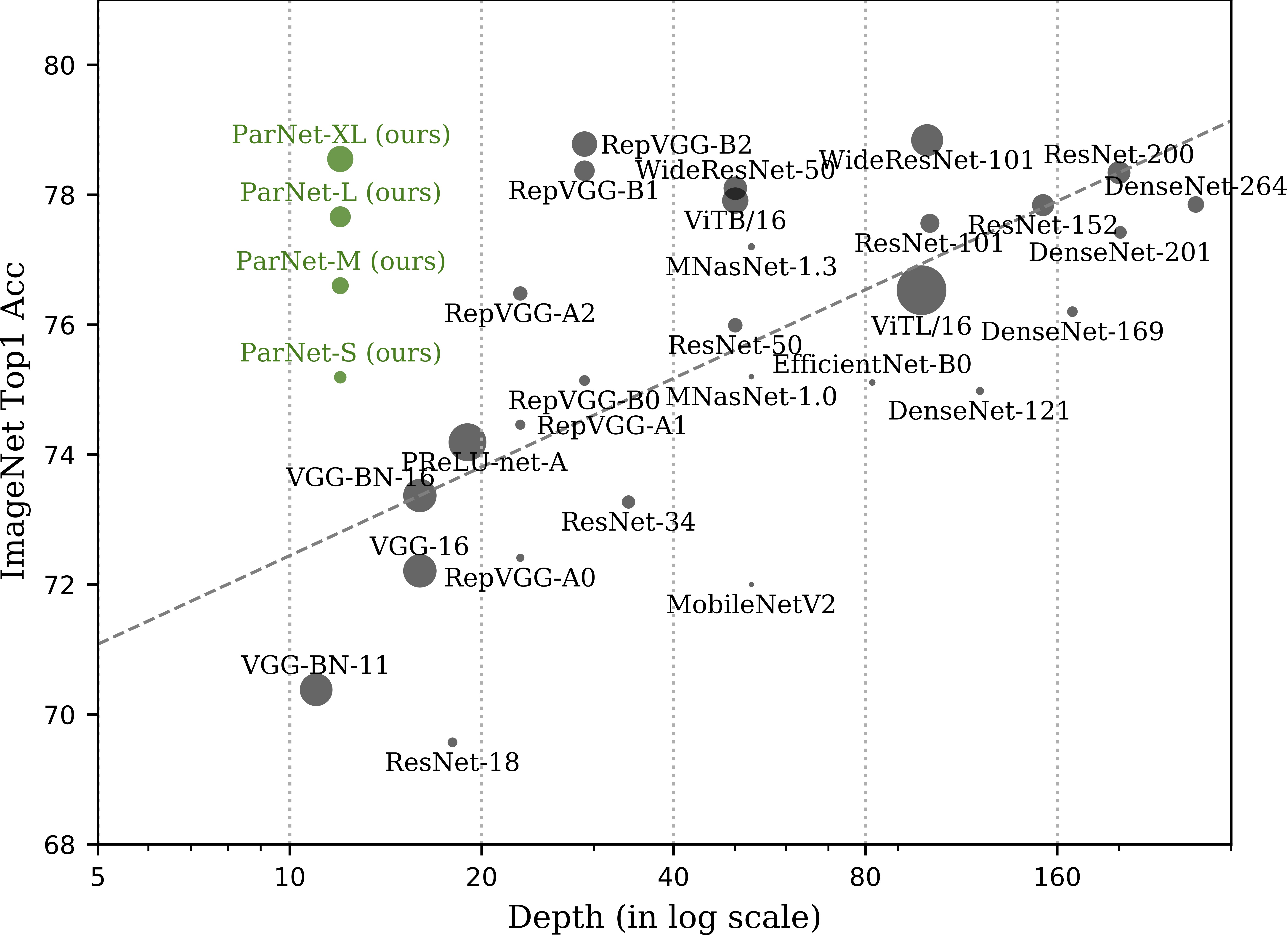
Depth is the hallmark of DNNs. But more depth means more sequential computation and higher latency. This begs the question -- is it possible to build high-performing ``non-deep" neural networks? We show it is. |
|
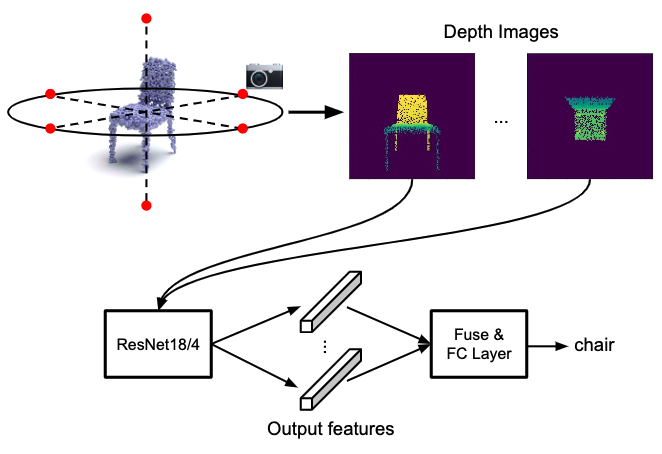
Many point-based approaches have been proposed reporting steady benchmark improvements over time. We study the key ingredients of this progress and uncover two critical results. First, auxiliary factors, independent of the model architecture, make a large difference in performance. Second, a very simple projection based method performs surprisingly well. |

|
Understanding spatial relations is important for both humans and robots. We create Rel3D, the first large-scale, human-annotated dataset for grounding spatial relations in 3D. The 3D scenes in Rel3D come in minimally contrastive pairs: two scenes in a pair are almost identical, but a spatial relation holds in one and fails in the other. |
|
Simultaneously reasoning about geometry and planning action is crucial for intelligent agents. This ability of geometric planning comes in handy while grocery shopping, rearranging room, warehouse management etc. We create PackIt, a virtual environment that caters to geometric planning. |
|
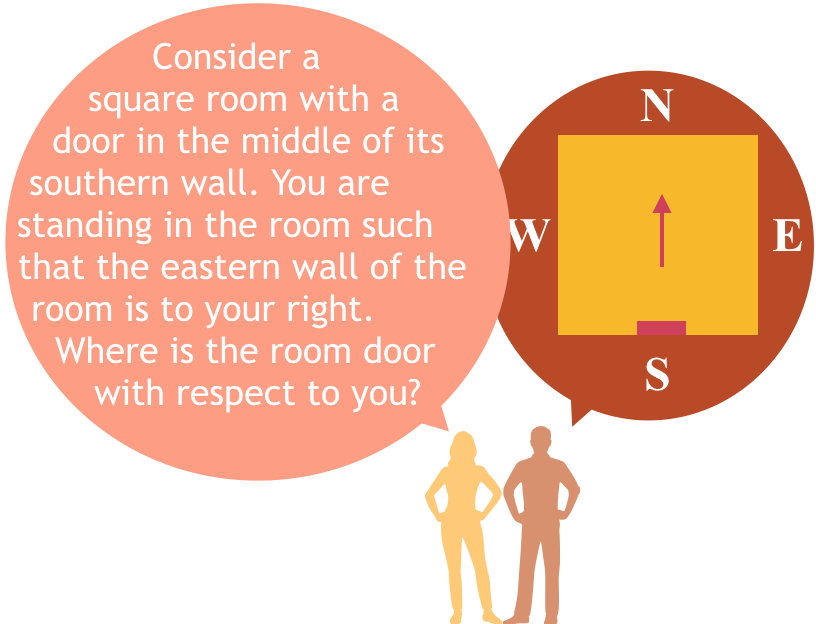
We study geometric reasoning in the context of question-answering. We introduce Dynamic Spatial Memory Network (DSMN), a deep network architecture designed for answering questions that admit latent visual representations. |
|
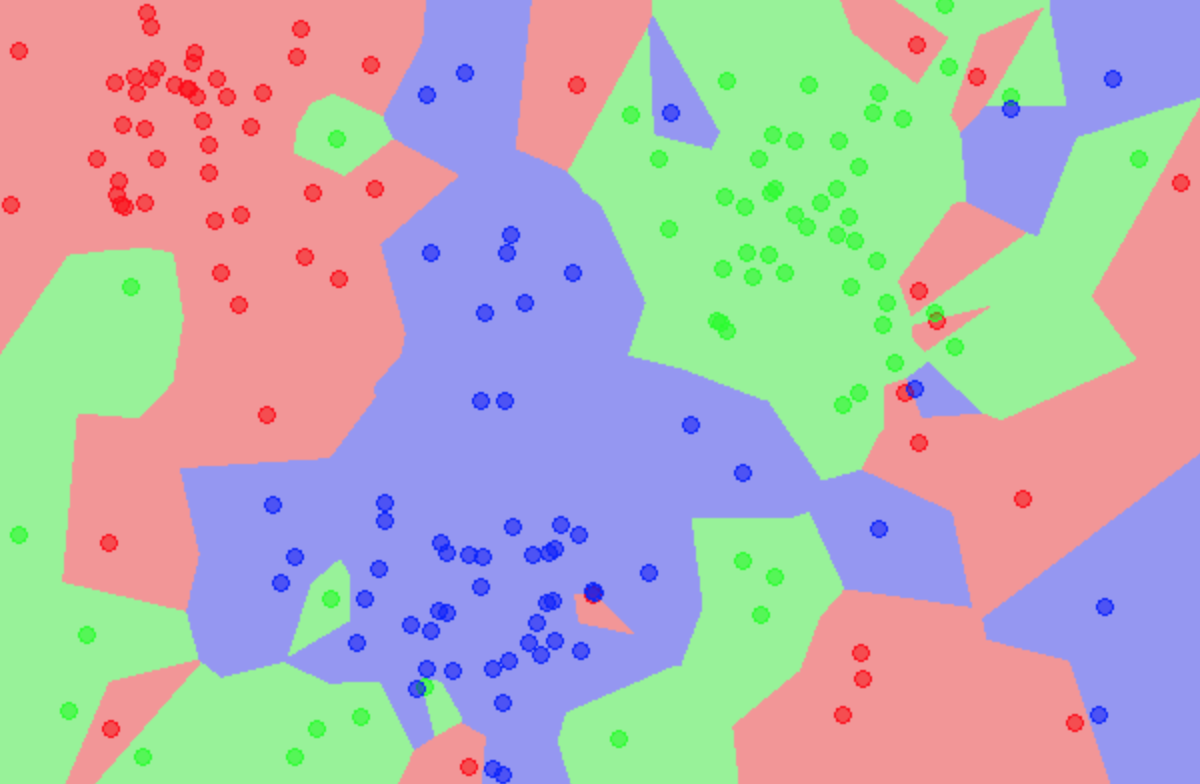
C Gupta, AS Suggala, A Goyal, HV Simhadri, BP, AK, SG, RU, MV, P Jain ICML 2017 [code] Prateek Jain, Chirag Gupta, AS Suggala, Ankit Goyal, HV Simhadri US Patent Applicaiton We propose ProtoNN, a novel algorithm that addresses the problem of real-time and accurate prediction on resource-scarce devices. |
|
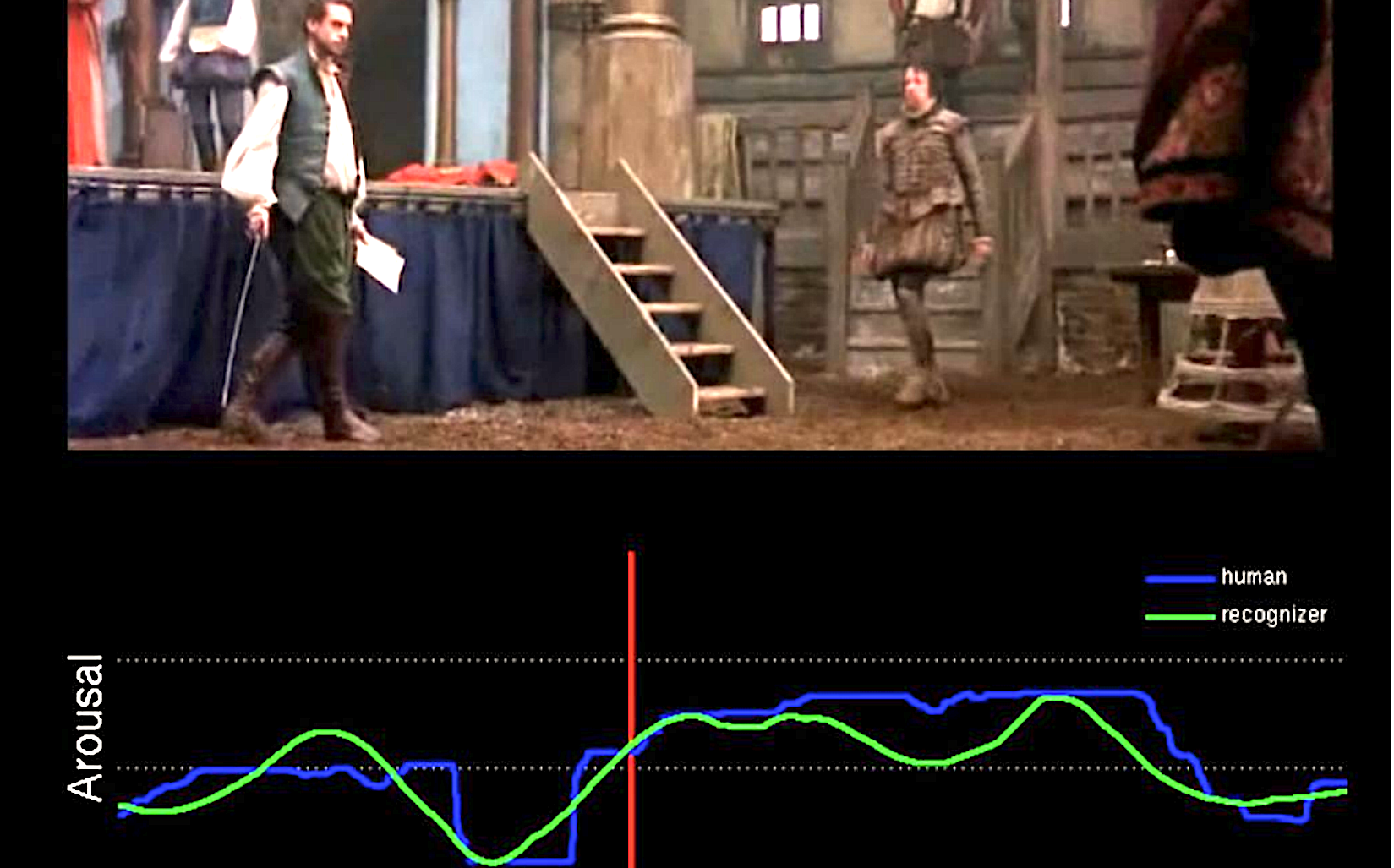
Ankit Goyal, Naveen Kumar, Tanaya Guha, Shrikanth S. Narayanan ICASSP 2016 We address the problem of continuous emotion prediction in movies. We propose a Mixture of Experts (MoE)-based fusion model that dynamically combines information from the audio and video modalities for predicting the emotion evoked in movies. |
|
|
Other coverage
|
|
|
|
|
|